You cannot select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
163 lines
8.2 KiB
Markdown
163 lines
8.2 KiB
Markdown
[简体中文](./README.md) / [捐助本项目](https://github.com/jianchang512/pyvideotrans/blob/main/about.md) / [Discord](https://discord.gg/TMCM2PfHzQ) / QQ Group 902124277
|
|
|
|
# Voice Recognition to Text Tool
|
|
|
|
This is an offline local voice recognition tool to text, based on the open-source model fast-whisper. It can recognize and convert human voice in videos/audios into text, in json format, srt subtitle with timestamps format, and plain text format. It can be used after self-deployment to replace the voice recognition interface of openai or Baidu Voice Recognition, etc. The accuracy is basically the same as the official api interface of openai.
|
|
|
|
>
|
|
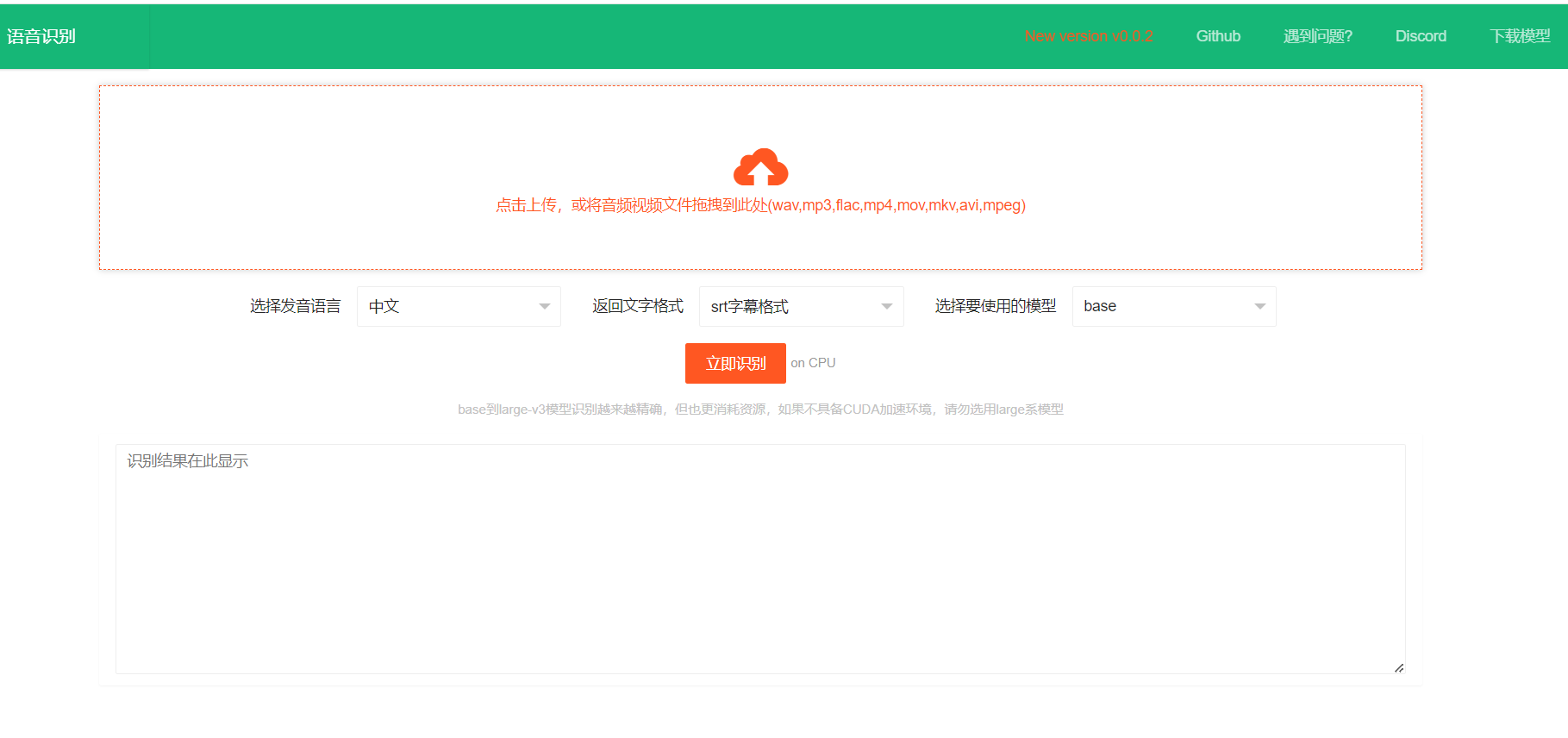
> After deployment or download, double click on start.exe to automatically call the local browser to open the local webpage.
|
|
>
|
|
> Drag or click to select the audio and video file to be recognized, then select the speaking language, output text format, model used (base model built-in), click start recognition, after completion, output in the selected format on the current webpage.
|
|
>
|
|
> The entire process does not require the internet, it operates entirely locally, and can be deployed on the intranet.
|
|
>
|
|
> The fast-whisper open-source model has base/small/medium/large-v3, with built-in base model, base->large-v3 recognition effect is getting better and better, but the computer resources required are also more, you can download and unzip it into the models directory according to need.
|
|
>
|
|
> [All model download links](https://github.com/jianchang512/stt/releases/tag/0.0)
|
|
>
|
|
|
|
|
|
# Video Demonstration
|
|
|
|
|
|
https://github.com/jianchang512/stt/assets/3378335/d716acb6-c20c-4174-9620-f574a7ff095d
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
# Precompiled Win Version Usage Method / Linux and Mac Source Code Deployment
|
|
|
|
1. [Click here to go to the Releases page to download](https://github.com/jianchang512/stt/releases) precompiled file
|
|
|
|
2. After downloading, unzip it somewhere, such as E:/stt
|
|
|
|
3. Double-click start.exe, and wait for the browser window to open automatically
|
|
|
|
4. Click on the upload area on the page, find the audio or video file you want to recognize in the pop-up window, or directly drag the audio and video file to the upload area, then select the spoken language, text output format, and model used, click "Start Recognition Immediately", wait for a while, the text boxes at the bottom will display the recognition results in the selected format
|
|
|
|
5. If the computer has an Nvidia GPU and the CUDA environment is correctly configured, CUDA acceleration will be used automatically
|
|
|
|
|
|
# Source Code Deployment (Linux / Mac / Window)
|
|
|
|
0. Required python 3.9->3.11
|
|
|
|
1. Create an empty directory, such as E:/stt, open cmd window in this directory, the method is to enter `cmd` in the address bar, and then press enter.
|
|
|
|
Using git to pull the source code to the current directory ` git clone git@github.com:jianchang512/stt.git . `
|
|
|
|
2. Create a virtual environment `python -m venv venv`
|
|
|
|
3. Activate the environment, the command under win is `%cd%/venv/scripts/activate`, the linux and Mac go to google and search. if want to use cuda,and exec `pip uninstall -y torch` ,`pip install torch --index-url https://download.pytorch.org/whl/cu121`
|
|
|
|
4. Install dependencies: `pip install -r requirements.txt`, if you report a version conflict error, please run `pip install -r requirements.txt --no-deps`
|
|
|
|
5. Decompress ffmpeg.7z under Windows, and put the `ffmpeg.exe` and `ffprobe.exe` in it in the project directory, linux and mac to download the corresponding version ffmpeg from the [ffmpeg official website](https://ffmpeg.org/download.html), unzip the `ffmpeg` and `ffprobe` binary programs and put them at the root of the project
|
|
|
|
6. [Download the model compression package](https://github.com/jianchang512/stt/releases/tag/0.0), download the model as necessary, after downloading, put the folder in the compression package into the models folder of the root of the project
|
|
|
|
7. Execute `python start.py `, wait for the local browser window to open automatically.
|
|
|
|
|
|
|
|
|
|
# API Interface
|
|
|
|
Interface address: http://127.0.0.1:9977/api
|
|
|
|
Request method: POST
|
|
|
|
Request parameters:
|
|
|
|
language: Language code: optional below
|
|
|
|
>
|
|
> Chinese: zh
|
|
> English: en
|
|
> French: fr
|
|
> German: de
|
|
> Japanese: ja
|
|
> Korean: ko
|
|
> Russian: ru
|
|
> Spanish: es
|
|
> Thai: th
|
|
> Italian: it
|
|
> Portuguese: pt
|
|
> Vietnamese: vi
|
|
> Arabic: ar
|
|
> Turkish: tr
|
|
>
|
|
|
|
model: Model name, optional below
|
|
>
|
|
> base corresponds to models/models--Systran--faster-whisper-base
|
|
> small corresponds to models/models--Systran--faster-whisper-small
|
|
> medium corresponds to models/models--Systran--faster-whisper-medium
|
|
> large-v3 corresponds to models/models--Systran--faster-whisper-large-v3
|
|
>
|
|
|
|
response_format: the returned subtitle format. Can be text|json|srt
|
|
|
|
file: audio and video files, binary upload
|
|
|
|
Api request example
|
|
|
|
```python
|
|
import requests
|
|
# Request address
|
|
url = "http://127.0.0.1:9977/api"
|
|
# Request parameters include file: audio and video files, language: language code, model: model, response_format: text|json|srt
|
|
# Returns code==0 success, others fail, msg==success is ok, others fail reasons, data=returned text after recognition
|
|
files = {"file": open("C:\\Users\\c1\\Videos\\2.wav", "rb")}
|
|
data={"language":"zh","model":"base","response_format":"json"}
|
|
response = requests.request("POST", url, timeout=600, data=data,files=files)
|
|
print(response.json())
|
|
```
|
|
|
|
|
|
|
|
# CUDA Acceleration Support
|
|
|
|
**Install CUDA Tools** [Detailed installation method](https://juejin.cn/post/7318704408727519270)
|
|
|
|
If your computer has Nvidia graphics card, first upgrade the graphics card driver to the latest, and then to install the corresponding
|
|
[CUDA Toolkit](https://developer.nvidia.com/cuda-downloads) and [cudnn for CUDA11.X](https://developer.nvidia.com/rdp/cudnn-archive).
|
|
|
|
After the installation is completed, press `Win + R`, type `cmd` and then press enter. In the pop-up window, type `nvcc --version`, confirm that there is version information displayed, similar to the graphic shown
|
|

|
|
|
|
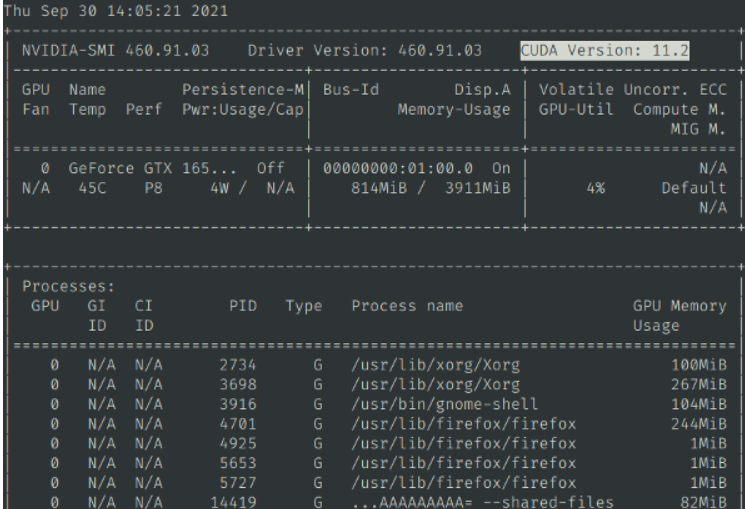
Then continue typing `nvidia-smi`, confirm there is output info and you can see the cuda version number, similar to the graphic shown
|
|
|
|
|
|
Then execute `python testcuda.py`, if it prompts success, it means the installation is correct, otherwise please carefully check and reinstall
|
|
By default, CPU operation is used. If you are sure to use a NVIDIA graphics card and have configured the CUDA environment, please modify the devtype=CPU in set.ini to devtype=CUDA and restart to use CUDA acceleration
|
|
|
|
# Notices
|
|
|
|
0. If you do not have Nvidia graphics card or the CUDA environment is not properly configured, do not use the large/large-v3 model, it may cause the memory to exhaust and crash
|
|
1. Chinese in some cases will output traditional characters
|
|
2. Sometimes you will encounter an error "cublasxx.dll does not exist", at this time you need to download cuBLAS, and then copy the dll file to the system directory, [click to download cuBLAS](https://github.com/jianchang512/stt/releases/download/0.0/cuBLAS_win.7z), after decompression, copy the dll file inside to C:/Windows/System32
|
|
3. By default, CPU operation is used. If you are sure to use a NVIDIA graphics card and have configured the CUDA environment, please modify the devtype=CPU in set.ini to devtype=CUDA and restart to use CUDA acceleration
|
|
|
|
|
|
|
|
# Related Projects
|
|
|
|
[Video translation dubbing tool: translate subtitles and dub](https://github.com/jianchang512/pyvideotrans)
|
|
|
|
[Voice Cloning Tool: Synthesize speech with any sound color](https://github.com/jianchang512/clone-voice)
|
|
|
|
[Vocal Background Music Separation: A very simple vocal and background music separation tool, localized webpage operation](https://github.com/jianchang512/stt)
|
|
|
|
# Acknowledgement
|
|
|
|
The other projects mainly dependent on this project are
|
|
|
|
1. https://github.com/SYSTRAN/faster-whisper
|
|
2. https://github.com/pallets/flask
|
|
3. https://ffmpeg.org/
|
|
4. https://layui.dev
|